Finding Differences Between Transformers and ConvNets Using Counterfactual Simulation Testing

Modern deep neural networks tend to be evaluated on static test sets making it hard to evaluate for robustness issues with respect to specific scene variations (e.g. object scale, object pose, scene lighting and 3D occlusions). Collecting real datasets with fine-grained naturalistic variations of sufficient scale can be extremely time-consuming and expensive. In our work, we present Counterfactual Simulation Testing, a framework that allows us to study the robustness of neural networks with respect to some of these naturalistic variations by building realistic synthetic scenes that allow us to ask counterfactual questions to the models, ultimately providing answers to questions such as "Would your classification still be correct if the object were viewed from the top?" or "Would your classification still be correct if the object were partially occluded by another object?". Our method allows for a fair comparison of the robustness of recently released, state-of-the-art Convolutional Neural Networks and Vision Transformers, with respect to these naturalistic variations. We find evidence that ConvNext is more robust to pose and scale variations than Swin, that ConvNext generalizes better to our simulated domain and that Swin handles partial occlusion better than ConvNext. We also find that robustness for all networks improves with network scale and with data scale and variety. We release the Naturalistic Variation Object Dataset (NVD), a large simulated dataset of 272k images of everyday objects with naturalistic variations such as object pose, scale, viewpoint, lighting and occlusions.
We release NVD, a dataset containing 272k images of 92 object models with 27 HDRI skybox lighting environments in a kitchen scene with 5 subsets of naturalistic scene variations: object pose, object scale, 360° panoramic camera rotation, top-to-frontal object view and occlusion with different objects. We hope that this dataset will allow for the study of generalization and robustness of modern neural networks. NVD was generated using MIT's ThreeDWorld platform.

Our proposed method of counterfactual simulation testing allows us to ask counterfactual questions to networks such as “Would your answer still be correct if I rotated the object by 60 degrees?” by simply (1) simulating a scene with the object of interest, testing both networks on that scene and (2) simulating a modified scene with a naturalistic variation, re-testing the networks and comparing the results. Our main metric is the proportion of conserved correct predictions, or PCCP. In essence, PCCP counts how many initial correct classifier prediction are still correct after we modify the scene/object in a specific manner. This metric is then averaged over different objects and scene lighting. This allows us to robustly compare two very different networks, by comparing their PCCP curves which tell us how robust the networks are to specific variations that we want to study (e.g. object size, object pose, etc.).
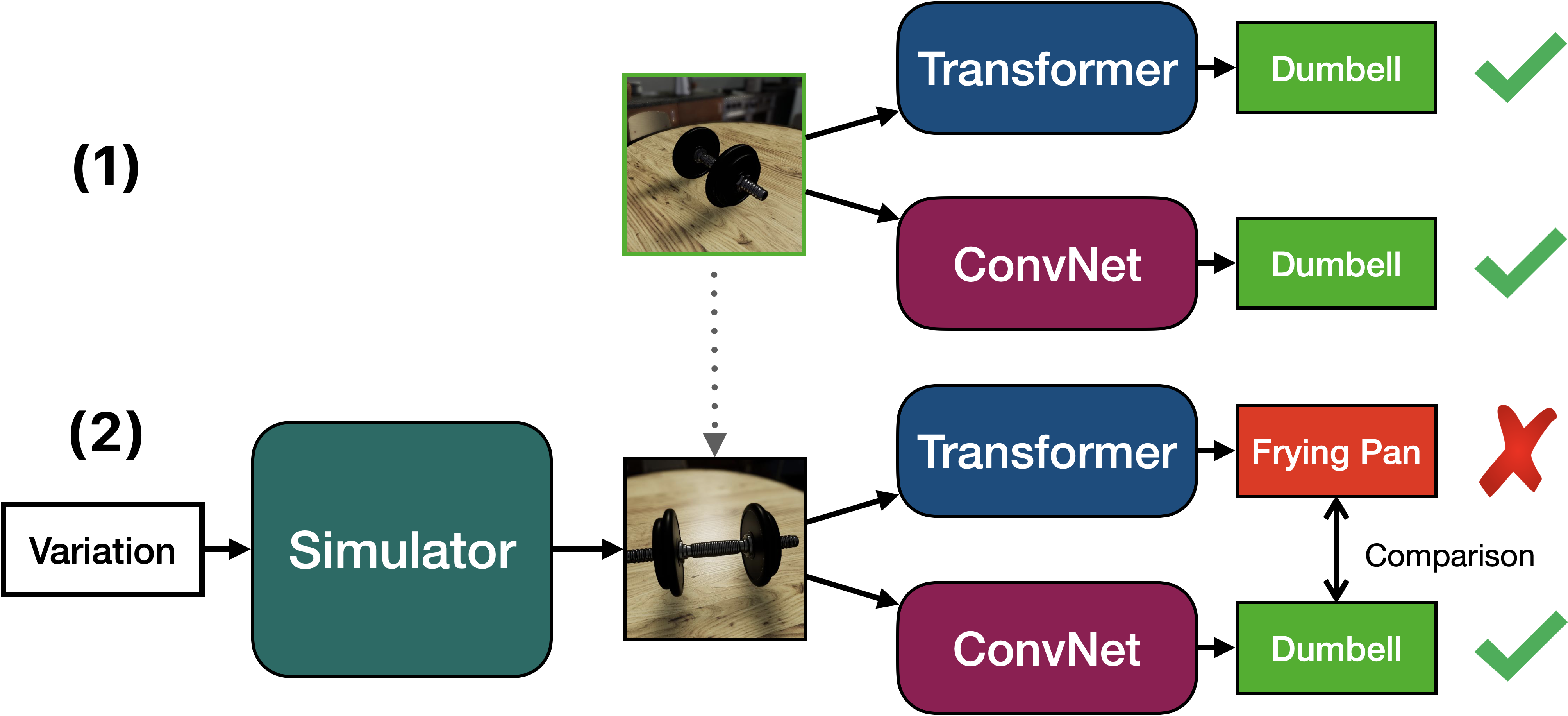
ConvNext and Swin are fragile with respect to naturalistic variations
For all five scene variations in our work, we see sharp drops in PCCP for both ConvNext and Swin networks of all sizes.
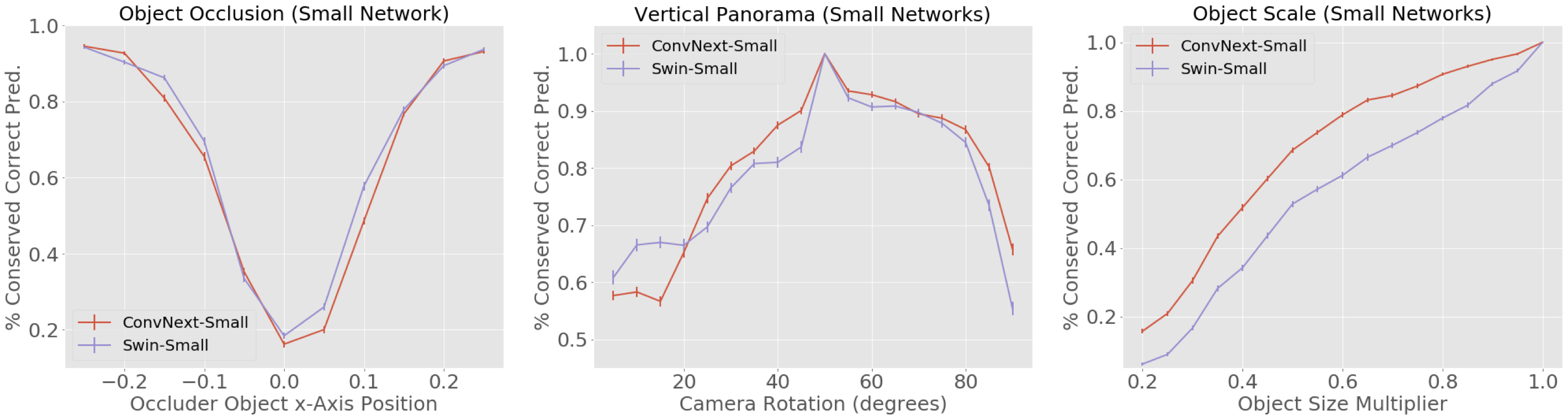
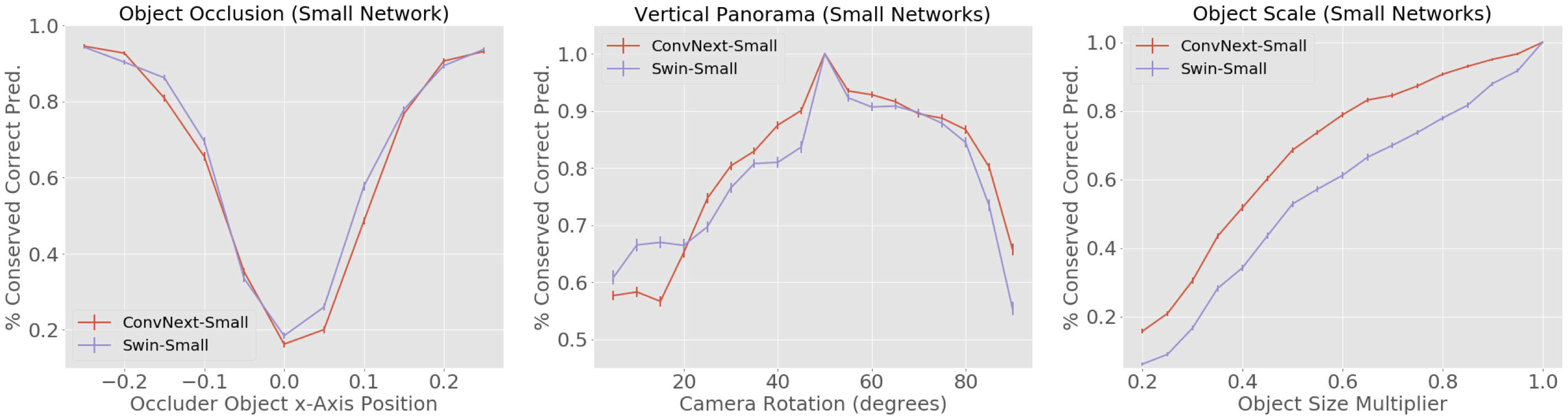
Robustness improves when networks get bigger and with more data and data variety
When we increase network size and train using ImageNet-22k instead of ImageNet-1k we see an increase in robustness (corresponding to flatter PCCP curves).
ConvNext is, on average, more robust to different object poses
ConvNext networks have, on average, higher conserved correct predictions than Swin networks for object rotations and viewpoint changes.
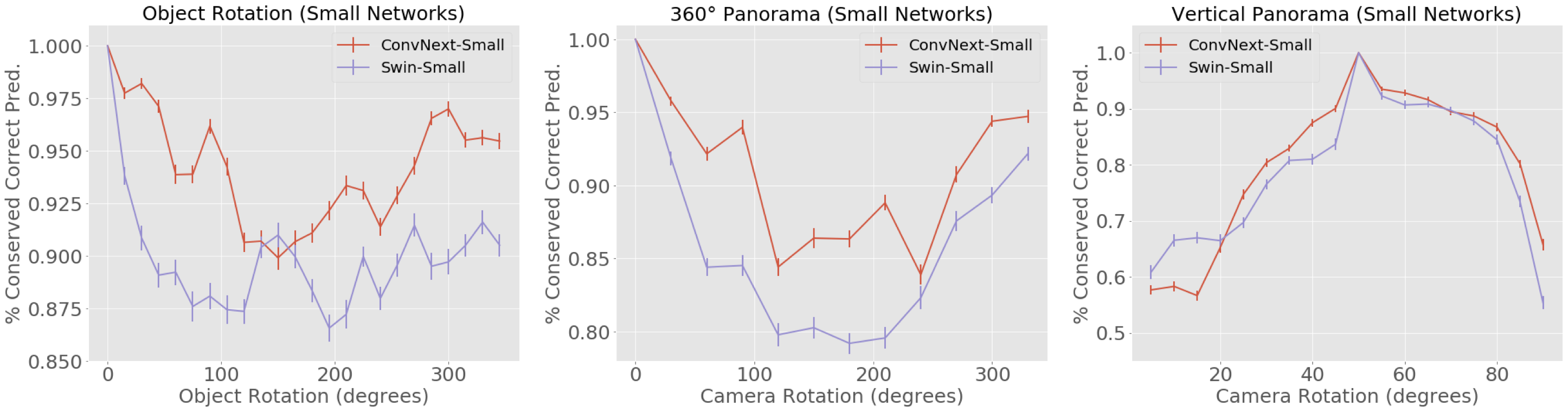
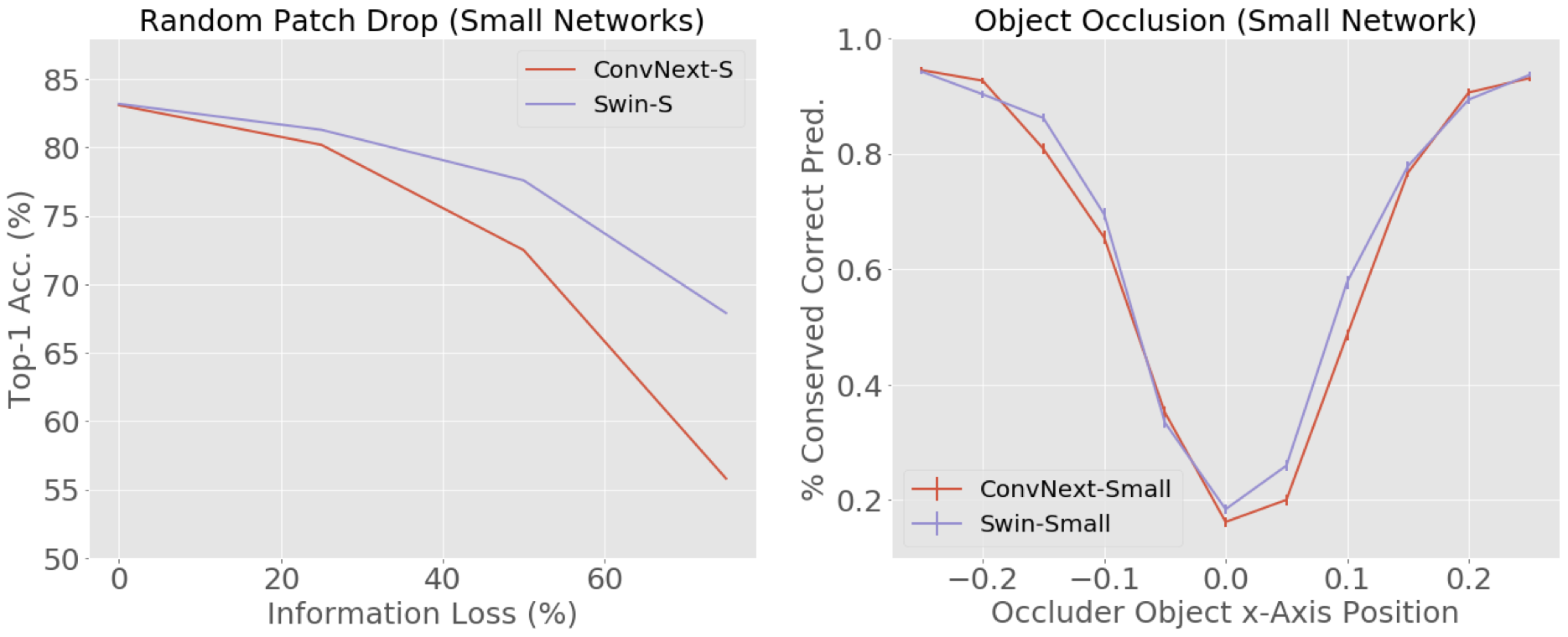
Swin is, on average, more robust to occlusion Swin Transformers are more robust to random patch drops when information loss is high - and on average more robust to occlusion by objects in NVD.
@article{ruiz2022counterfactual,
title={Finding Differences Between Transformers and ConvNets Using Counterfactual Simulation Testing},
author={Ruiz, Nataniel and Bargal, Sarah Adel and Xie, Cihang and Saenko, Kate and Sclaroff, Stan},
booktitle={Advances in Neural Information Processing Systems},
year={2022}
}
Acknowledgements: We deeply thank Jeremy Schwartz and Seth Alter for their advice and support on the ThreeDWorld (TDW) simulation platform.